Tier 1 US Telecom — Unified Topology Graph Platform (Ingestion + Stitching)
Summary
Built a standards-aligned topology platform that ingests inventory from 30+ OSS sources, normalizes to TMF SID + ITU M.3100, persists into Neo4j, and stitches relationships in both bulk and real time—enabling query-in-seconds traversals for service impact and assurance.
Problem
Topology and inventory lived in heterogeneous systems (MongoDB, Oracle, legacy OSS, flat files). Schemas conflicted, lineage was unclear, and assurance teams lacked a single, trustworthy view. Impact analysis required manual joins; queries took hours, CMDB replicas drifted, and integration costs rose with every new source.
Solution Mechanics
- Multi-source CDC ingestion via Kafka Connect (Mongo/Oracle/file/legacy interfaces).
- Canonical modeling to TMF SID + ITU M.3100 (equipment, termination points, connections, capacity, alarms).
- Stream + batch processing with Apache Flink and Spring Batch for backfills.
- Neo4j as the read-optimized topology store; GraphQL/REST for traversal and downstream replication.
- Rules-driven stitching:
- Rules Templates stored in MongoDB (JSON).
- A Java rules library generates Cypher and enforces relationship uniqueness.
- Two paths: bulk (historical) and real-time (CDC events).
- Validation & remediation run in parallel (constraints, rule engine, audited invalid store) to keep integrity high.
Diagram 1 — System Flow
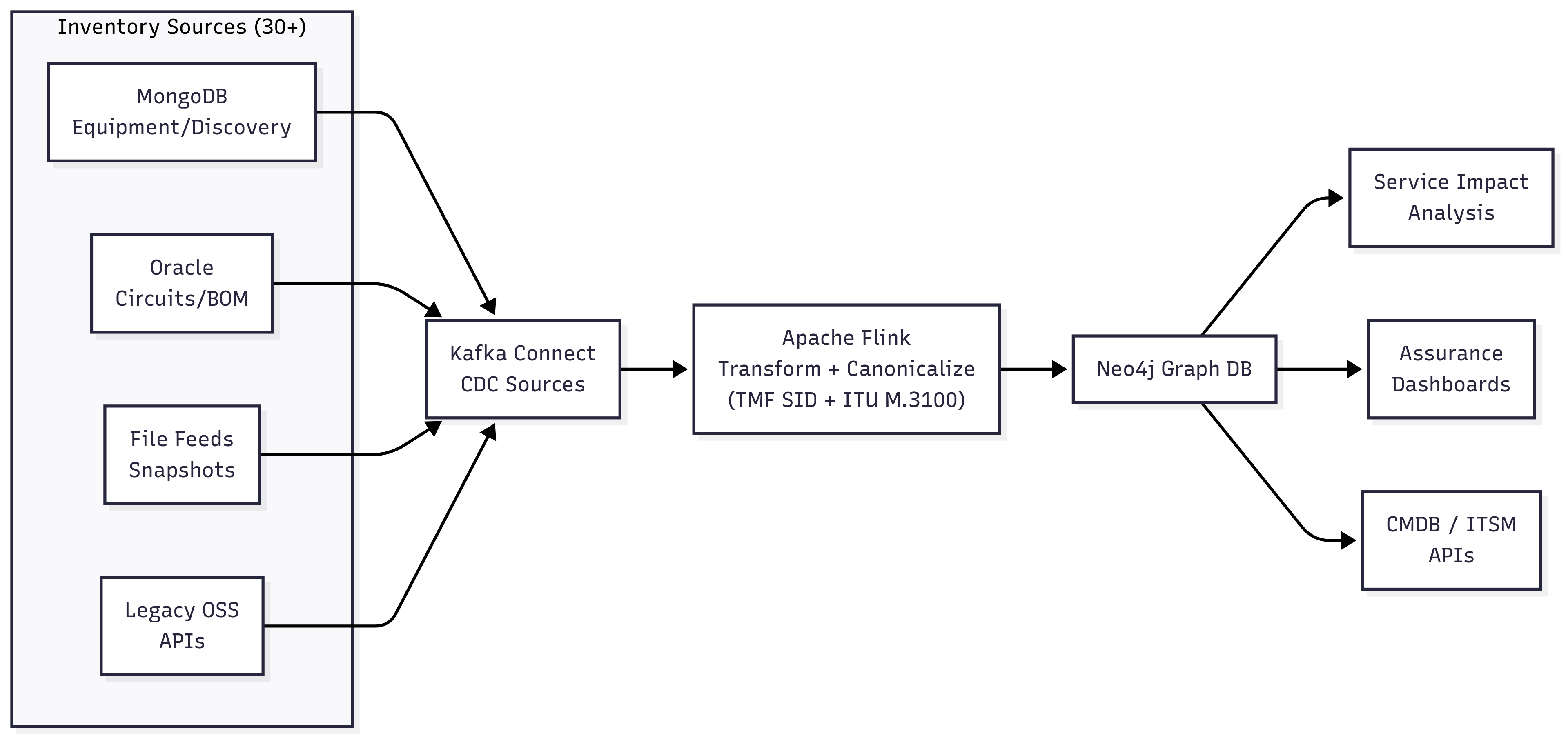 Multi-source CDC → Flink transform → Neo4j → assurance/CMDB consumers.
Multi-source CDC → Flink transform → Neo4j → assurance/CMDB consumers.
Diagram 2 — Rules-Driven Stitching
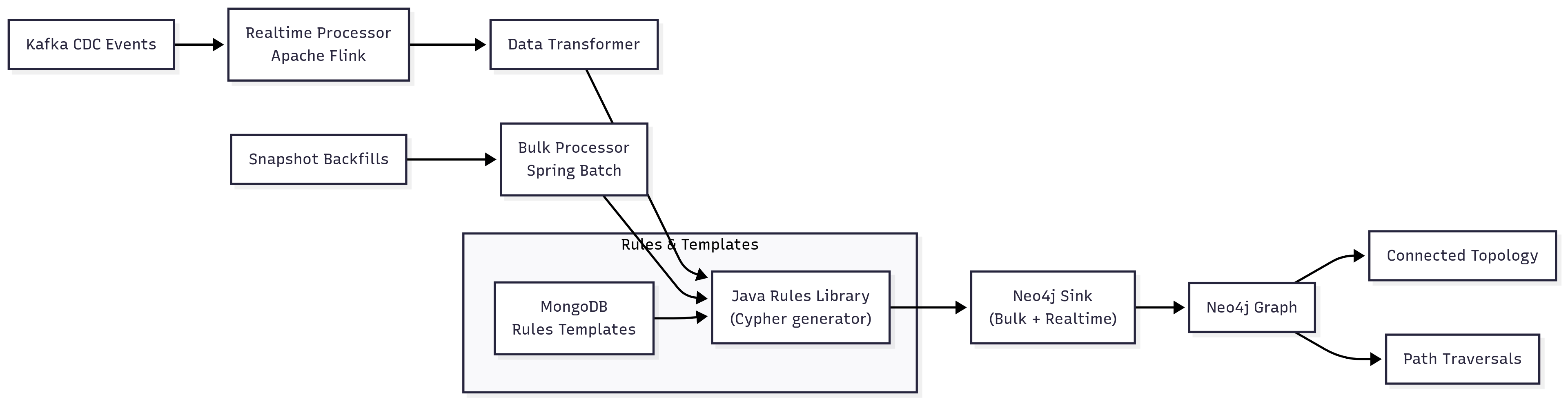 Templates in MongoDB → rules processor → Cypher → Neo4j sink (bulk + real-time).
Templates in MongoDB → rules processor → Cypher → Neo4j sink (bulk + real-time).
How it works (step-by-step)
- CDC connectors capture changes from MongoDB / Oracle / file feeds / legacy OSS.
- Events land in Kafka (topics partitioned by entity/type, idempotent keys).
- Apache Flink normalizes to TMF SID + ITU M.3100 and enriches with lineage.
- Nodes & properties are upserted into Neo4j with constraints and relationship uniqueness.
- A stitcher (Flink realtime + Spring Batch bulk) loads MongoDB rules templates, generates Cypher, and creates relationships.
- Validation classifies records (valid / remediable / invalid); invalids go to an audited store with remediation loops.
- Consumers (assurance dashboards, GraphQL/REST, CMDB replicate) query the connected graph in seconds.
- Backfills run in bulk windows while CDC maintains freshness with DLQs, backpressure, and controlled replay.
Outcomes
- Single source of truth for topology spanning 30+ systems.
- Near-real-time freshness through CDC with idempotent upserts and DLQs.
- End-to-end traversals (Equipment → TPs → Connections → Capacity → Customer) in seconds, not hours.
- Reduced defect leakage via validation and remediation loops (audited invalids, rule-backed fixes).
- Plug-and-play consumers: assurance dashboards, CMDB replication, GraphQL impact APIs.
Strategic Business Impact
-
MTTR reduction on correlation-heavy incidents (Modeled; Med–High confidence)
Assumptions: baseline MTTR, % incidents requiring topology correlation, path-finding time cut from hours → minutes.
Modeled outcome: 20–40% MTTR reduction for those incidents → fewer customer-visible minutes. -
Integration cost avoidance (Proxy)
Standards-aligned model + reusable connectors reduced per-source mapping/rework. -
Assurance capability uplift (Proxy)
“Query-in-seconds” impact assessments replaced manual joins—faster decisions during events.
Method tags: MTTR = Modeled; Cost avoidance & capability uplift = Proxy.
Evidence hooks: traversal timings, incident post-mortems, connector catalog, runbooks.
Role & Scope
- Led end-to-end architecture across ingestion, canonical modeling, Neo4j persistence, API exposures, and rules-driven stitching.
- Aligned discovery/planning/CMDB/assurance teams on model contracts, SLAs, and governance (versioned rules, invalid-data workflow, DLQ recovery).
Key Decisions & Trade-offs
- Standards first (TMF/ITU): higher up-front modeling, lower lifetime integration cost; avoids schema drift.
- Graph as topology system of record: fast traversals and impact analysis; tuned constraints/APOC and batching for write throughput.
- Rules outside code: faster iteration; enforced versioning, testing, and rollout gates.
- Dual stitching paths (bulk + real-time): correctness for backfills, freshness for CDC; dedupe/uniqueness rules to prevent duplicates.
- CDC over scheduled ETL: higher freshness; required idempotency and backpressure controls.
Risks & Mitigations
- Rule explosion / write contention → constrained rule grammar, pre-validation, batched Cypher, relationship uniqueness, bulk windows.
- CDC volume spikes / lag → DLQs with auto-replay, backpressure, snapshot markers.
- Model drift across sources → canonical schema registry + contract tests per connector.
- Skewed relationship creation → partitioned processing, p95 write SLOs, adaptive batch sizing.
Suggested Metrics (run-time SLOs)
- CDC lag p95 per source; DLQ depth & recovery time.
- Traversal latency p50/p95 by path length; relationship creation throughput per entity.
- Invalid→valid remediation rate; constraint violation rate (trend).
- Consumer freshness for CMDB/assurance datasets.
Principle carried forward:
Standards-aligned models, CDC correctness, rules-driven stitching, and graph-first assurance are the fastest route from data silos to reliable operations at telecom scale.