Tier 1 US Telecom - Device Reconciliation Framework (Network Inventory)
Summary
Designed and implemented an end-to-end platform that continuously reconciles network devices between discovery databases and planning/inventory systems. The framework extracts from multiple sources, performs exact / regex / fuzzy matching, auto-creates missing devices through a template-driven API, and provides market/global reporting with notifications and dashboards.
Problem
Discovery and planning inventories drifted over time: devices existed in one system but not the other, identifiers diverged, and manual matching didn’t scale. This caused provisioning delays, support tickets, and low confidence in inventory accuracy—especially before rollout windows.
Solution Mechanics
-
Module 1 — Discovery Extraction
- Pulls device records from MongoDB, Oracle, PostgreSQL, BigQuery, file feeds (configurable templates).
- Stores extracted snapshots in PostgreSQL for consistent downstream processing.
- Schedules, retries, execution metadata, and DLQ for failures.
-
Module 2 — Planning Extraction & Matching
- Loads planning records (MongoDB/Oracle) and matches against discovery via exact, pattern/regex, and fuzzy (Levenshtein/Jaro-Winkler) techniques.
- Persists matched/unmatched sets with confidence scores and run IDs; snapshot-based recovery; parallel workers.
-
Module 3 — Missing Device Handling & Creation
- For devices missing in planning, fetches equipment templates (by vendor/model) and location details.
- Submits batch creation requests to the equipment creation API; prevents duplicates by re-checking planning before retries; limits and DLQ for persistent failures.
-
Module 4 — Reporting & Notifications
- Aggregates per-market and global stats (matched %, missing count, create success/fail, retries).
- Email/Slack notifications; Grafana dashboards (summary + drill-down).
- Optional pre-run notifications so stakeholders can pause a scheduled reconciliation.
Diagram 1 — Reconciliation pipeline Overview
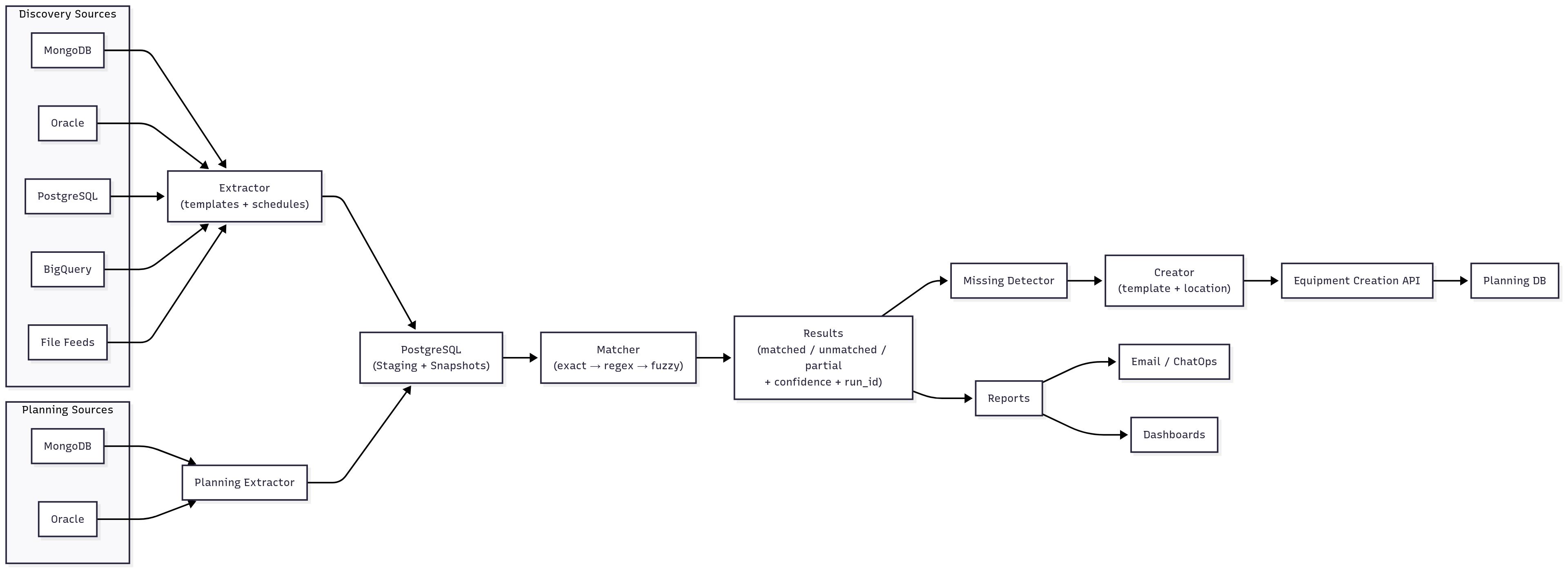
Diagram 2 — Matching Mechanics & Confidence
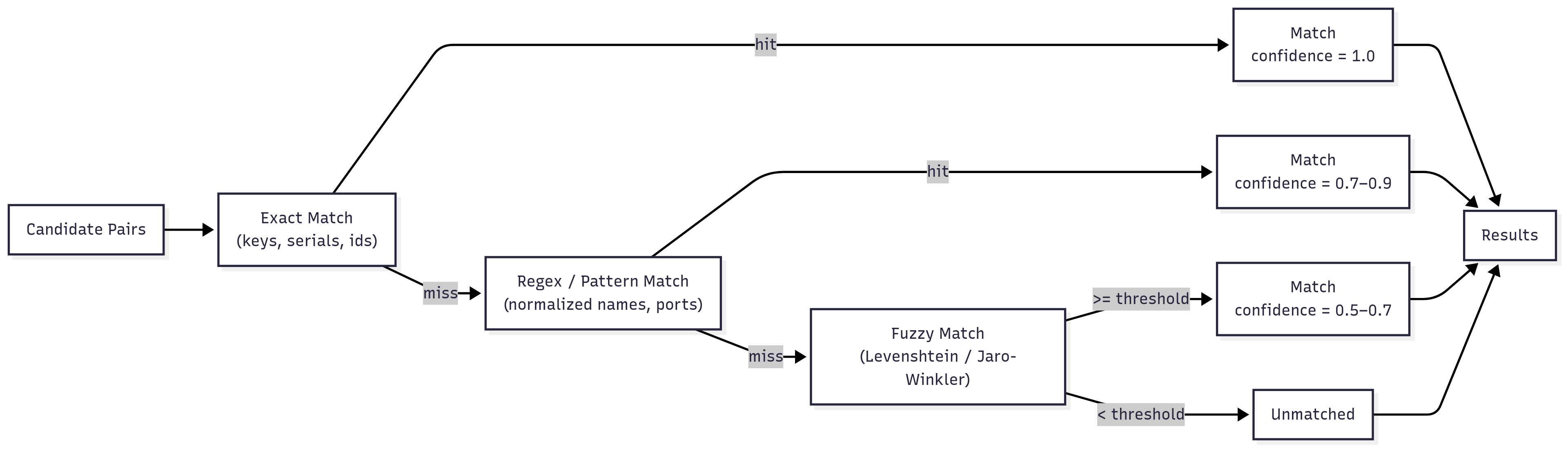
Diagram 3 — Missing Device Creation, Retry & DLQ Flow

Process Flow
- Extract discovery records (multi-source) into PostgreSQL with run metadata.
- Extract planning records for the same scope/market.
- Match discovery↔planning via exact → regex → fuzzy, assigning confidence scores.
- Persist results (matched / unmatched / partial) with run_id and stats.
- Identify missing devices in planning; fetch template + location data.
- Batch-create devices via equipment creation API; record success/failure.
- Retry transient errors with limits; prevent duplicates by pre-retry existence checks; push hard failures to DLQ.
- Publish reports and notify stakeholders; dashboards update for trend analysis.
Outcomes
- Inventory accuracy up: systemic reconciliation across markets; fewer “ghost” or “orphaned” devices.
- Provisioning readiness improved: missing equipment created in batches before rollout windows.
- Operational visibility: single place to see reconciliation stats, failures, and retries by market/run.
- Lower manual effort: auto-matching and creation reduced spreadsheet triage and hand-entered tickets.
Strategic Business Impact
-
Reduced manual reconciliation hours (Modeled)
Assumes baseline manual throughput and match rates; automation replaces repetitive lookups and keystrokes. -
Faster time-to-provision (Proxy)
Creating missing devices ahead of change windows decreases rollbacks and scheduling churn. -
Risk reduction (Proxy)
Accurate planning inventory reduces downstream assurance and CMDB inconsistencies.
Method tags: Manual effort = Modeled; Provisioning speed & risk = Proxy.
Evidence hooks: matched %, missing→created %, retries, DLQ depth, time from extraction→ready.
Role & Scope
- Owned the architecture and delivery across extraction, matching, creation, and observability.
- Defined query-template governance, matching confidence policy, duplicate-prevention logic, DLQ strategy, and the market/global reporting model.
- Aligned platform, inventory, and field ops teams on SLAs and runbooks.
Key Decisions & Trade-offs
- Template-driven queries: low-code modifications per market/source; requires disciplined versioning.
- In-memory matching: fastest for batch runs; paired with snapshot checkpoints for crash recovery.
- Batch creation: API efficiency vs. per-device audit—solved with detailed per-record metadata.
- Retry with guardrails: re-check planning before retry to avoid duplicates; cap max retries.
- Centralized metadata: every module writes to a shared schema to enable cross-module reporting.
Risks & Mitigations
- False matches → multi-stage matching (exact→regex→fuzzy) + confidence thresholds and manual review queues.
- Duplicate creation → pre-retry existence check in planning DB; idempotency keys on API.
- Source throttling → pagination + backoff; batch windows aligned to change freezes.
- Skewed markets → parallel workers with per-market caps; DLQ isolation and replay.
Suggested Metrics (run-time SLOs)
- Match rate (exact/regex/fuzzy %), confidence distribution.
- Missing→created conversion rate, API success rate, retry rate, max retries exceeded.
- DLQ depth & recovery time, snapshot resume count.
- End-to-end latency (extract → ready), per-market throughput.
Principle carried forward:
Treat reconciliation as a first-class pipeline with templates, staged matching, safe creation, and audit-grade observability—so inventory stays trustworthy and rollout windows stay on schedule.